Since its founding in 2008, GitHub has risen to become the preeminent worldwide platform for software development and version control. Currently, 72% of the Fortune 50 and more than 3 million organizations leverage GitHub daily—including over 65 million total developers and over 200 million repositories, according to their home page.
With so many critical resources hosted there, having the means to back up and restore all that data is essential. Failures aren’t unheard of; relying solely on GitHub availability introduces the risk of data loss. Additionally, companies adhering to the time-tested 3-2-1 backup strategy realize that redundancy is key to safeguarding information. GitHub also hosts both public and private repositories.
The fact remains that many teams provide critical coding resources (and documentation) in an open-source fashion or keep proprietary information under lock and key. No development team wants to lose its progress; accordingly, backup solutions can be beneficial for any project stakeholders—both internal and external. These measures help protect against the following:
- Account compromises
- Ransomware attacks
- Accidental repository deletion
- Service downtime
- Platform dependence
- Compliance issues
How should teams tackle this responsibility? Two primary approaches—bespoke solutions and third-party software—are available for GitHub users. This article will break down both methods and answer the pivotal question: Should I build or should I buy?
Pros of a Bespoke GitHub Backup Solution
As with any first-party solution, most benefits boil down to increased control. Companies and internal teams can design their backup solutions as they see fit, implementing their own controls, preferred technology stacks, and coding implementations. Accordingly, developers can marry backend and frontend designs however they wish. The opportunity for customization is nearly limitless. It’s relatively easy to determine what to back up, which mechanisms that can happen through, and how internal resources may tie into resulting backups.
Additionally, you can back up as frequently as you wish with a bespoke solution. While third-party tools may only permit backups—often called snapshots—at certain intervals, you can calibrate internal solutions to back up daily. This is even possible multiple times daily. If that ambitious backup schedule is essential, then an in-house approach may be ideal.
Finally, bespoke backups can point to whichever storage solution you prefer. This is especially useful when weighing multiple cloud-based storage options against one another without introducing vendor lock-in or dependency into the equation. Companies can also point backups toward on-premises drives for extra peace of mind.
How to Create Your Own Basic Backup Solution
So perhaps you’ve decided that a bespoke backup is right for you. Thankfully, there are available open-source resources that let you do away with the need to completely start from scratch. That doesn’t mean you can’t hand-code everything, but that development commitment isn’t mandatory.
For example, GitHub offers its own Migrations API. This makes it easier for enterprise customers, primarily, to move repositories from GitHub.com to GitHub Enterprise Server. Accordingly, only authenticated owners are permitted to initiate this process. Migrated repositories are locked until manually unlocked, and GitHub archives all migrations for seven days before they’re autodeleted.
API Usage Procedures
Let’s cover the requests available via the Migrations API.
To jump-start the creation of a migration archive:
POST orgs/{org}/migrations
Key parameters, such as repositories, are needed to designate targeted repositories for migration. GitHub recognizes that backups can also be sizable; mixed media types and attachments can devour storage capacity if mismanaged.
Luckily, the exclude_attachments parameter allows you to exclude these large files to save space.
Similarly, data integrity is equally critical during the backup process as it is with resting data. The lock_repositories attribute prevents data manipulation while the process is ongoing. Finally, GitHub requires defining the application/vnd.github.wyandotte-preview+json media type within the Accept header. It’s also recommended that you include the application/vnd.github.v3+json header string.
To see this in action, a Bash user may enter the following shell command:
curl
-X POST
-H "Accept: application/vnd.github.v3+json"
https://api.github.com/orgs/ORG/migrations
-d '{"repositories":["repositories"]}'
To get a migration status:
curl
-H "Accept: application/vnd.github.wyandotte-preview+json"
https://api.github.com/orgs/ORG/migrations/42
To download a migration archive tied to your organization:
curl
-H "Accept: application/vnd.github.wyandotte-preview+json"
https://api.github.com/orgs/ORG/migrations/42/archive
To unlock a repository:
curl
-X DELETE
-H "Accept: application/vnd.github.wyandotte-preview+json"
https://api.github.com/orgs/ORG/migrations/42/repos/REPO_NAME/lock
You may also delete and list any migrations, plus perform a number of requests related to imports. After downloading your archive, GitHub explicitly suggests uploading to a cloud service, like Google Drive or Dropbox—or even external hard drives.
However, it’s possible to utilize other cloud services if preferred. Note that this method isn’t necessarily automated since it requires user action during most steps.
Third-Party Coding
Multiple developers on GitHub have published their own open-source code blocks to help kick-start the backup process. These projects are commonly called scripts, and the GitHub community publicly maintains them. The idea is that these scripts are generic enough to be usable in a variety of deployments. By and large, these solutions leverage Python, Ruby, or Bash to provide functionality. Some popular, modular backup scripts are as follows:
- abusesa
- rodw
- camptocamp (now archived and read-only)
- testmycode
It’s important to remember that community backup resources are inherently more volatile than their vendor-backed counterparts. The nature of open-source, community-based solutions means that they’ll have shorter life cycles on average. There’s also a form of competition in the open-source community, as everyone is hoping (albeit more altruistically) to design better solutions constantly. The good news is that even read-only projects may be implemented or become building blocks for bespoke solutions.
Authentication is also key for these scripts. You must still verify your identity via personal GitHub tokens. Generating new tokens allows you to access your intended repositories—public or private—and define your backup scope. Users and organizations are also configurable. This is the case (in a very nutty nutshell) for the abusesa solution, for example.
Cons of a Bespoke Solution
A bespoke backup procedure may sound appealing, yet no system is perfect. Making your own backup solution means incurring a lot of expense to get right—from inception to development to maintenance. Will you have enough team members to effectively oversee this solution throughout its lifetime? These are uncertainties worth addressing before making the decision to go with a bespoke backup solution. It’s true that open-source resources can dampen initial costs, but long-term expenses will be noteworthy.
Accordingly, there’s also a fair amount of effort required to devise such a solution. Many man-hours are needed to make something functional and reliable. Essentially, you’re creating a backend to serve multiple purposes by leveraging APIs. Development time increases if you wrap a GUI around everything. There are very few out-of-the-box functionalities to be had. These APIs must be kept current, and validation testing takes a lot of time to really nail. That’s doubly true for companies without optimized CI/CD and DevOps pipelines (a.k.a., low performers, according to Google’s DORA blog.)
It then becomes much more essential to amass expertise within your organization. Experienced professionals are needed to create and really understand how a bespoke backup solution works. What happens if these keepers of the keys leave the organization later on? Sound documentation becomes another priority. Your team is essentially becoming its own software vendor.
Finally, it’s worth questioning whether you can fully trust your internal solution even in the best-case scenario. How will unforeseen development mistakes, testing errors, and backup failures impact your data? In the case of an emergency, will you be able to restore your data correctly – and within a reasonable time frame? A backup isn’t much good if you can’t use it to actually restore your code.
After all, GitHub project resources are critical to a company’s development pipeline—impacting reputation, efficiency, and security. IP loss can even threaten your company’s existence if the fallout is grand enough. Can third-party solutions do a better job?
Pros of Purchasing a Backup Solution
When we assess some core negatives with the bespoke route, the inverse soon becomes true for external solutions. Your development team saves time that would’ve been allocated to backup creation and can harness it for other projects. Building and maintaining are already handled by the vendor. Similarly, ongoing updates and security fixes are pushed without involvement from your team.
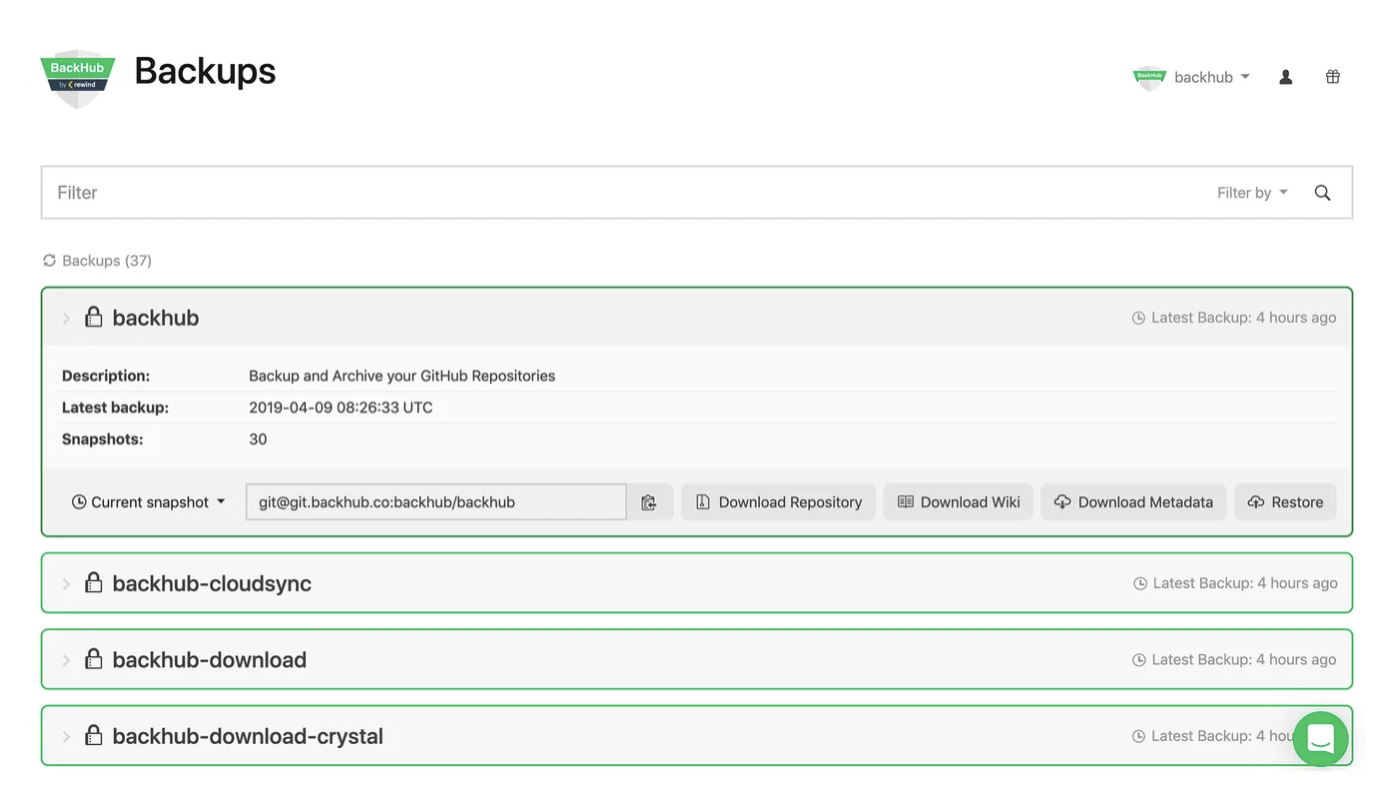
While some initial setup is required, it’s possible to lock in your settings and forget. Blissfully watch as your tool handles recurring backups automatically. Additionally, no special code or experience is needed to set up these turnkey programs. Third-party backup solutions, like BackHub, a Rewind product, come with batteries included.
BackHub automatically creates daily recurring backups of public and private repositories across your organization. Backups include not only the repository with all branches, but also all associated metadata, which can be cloned or restored back into GitHub. A complete audit log of all activity is available for additional security.
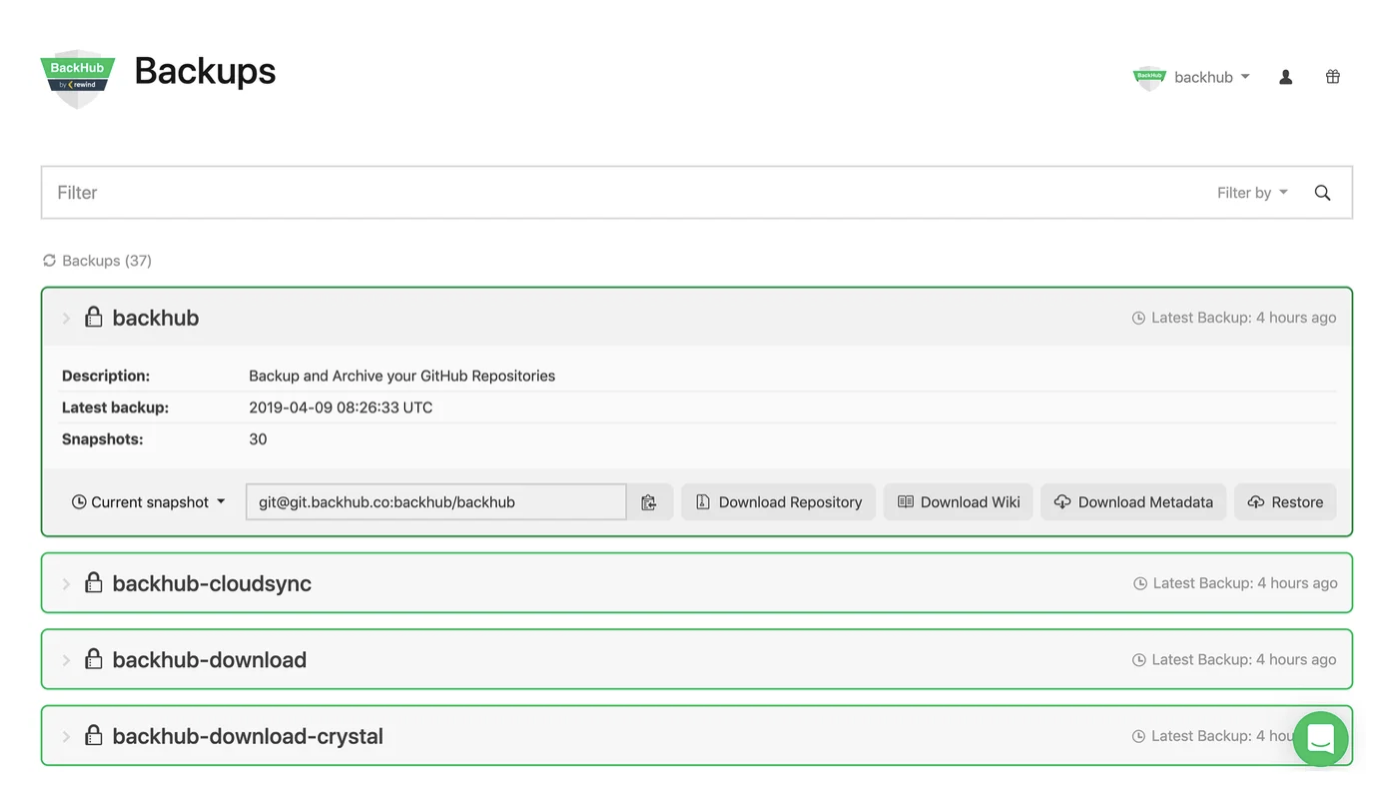
BackHub also allows for automatic sync with external storage. Backups can be automatically synced to a private AWS S3 bucket for an easy to manage off-site backup.
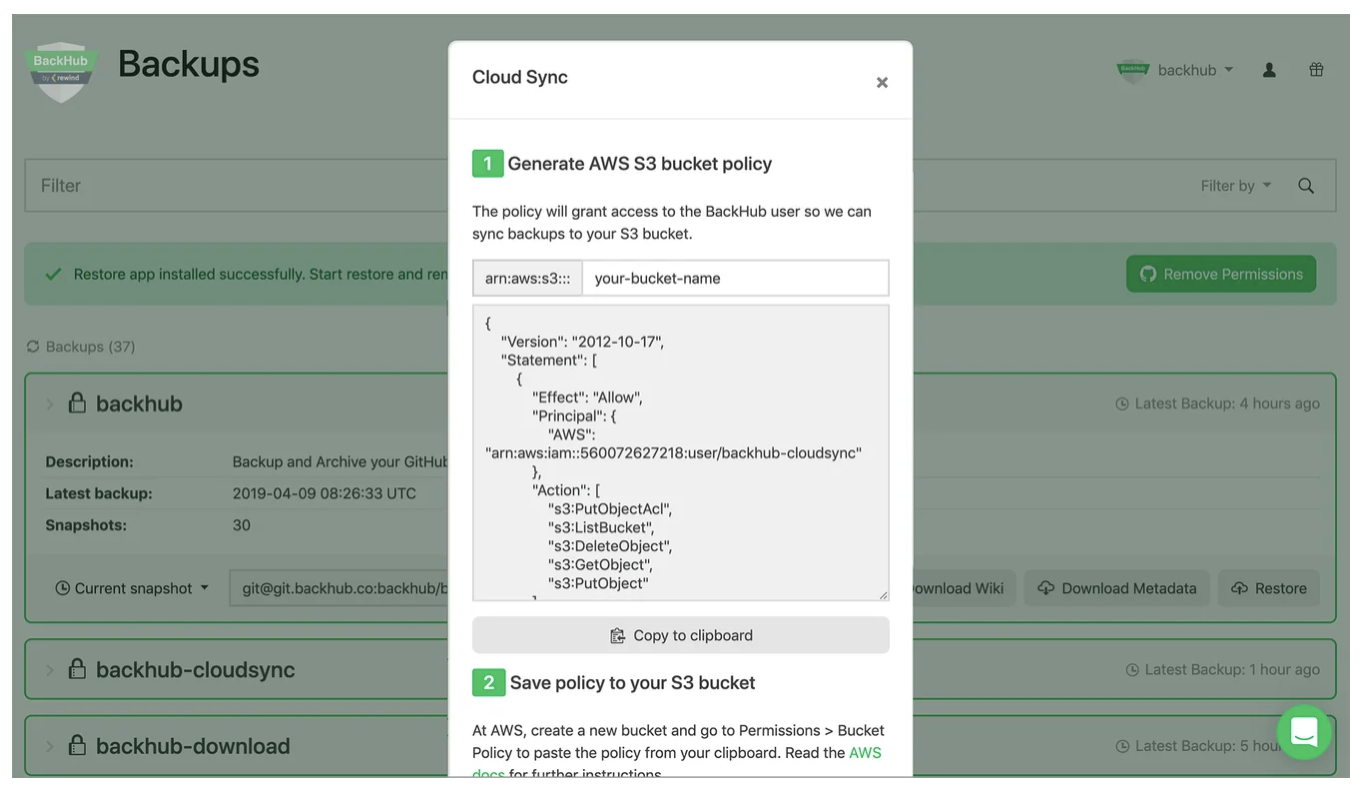
The tool’s developers work to ensure compliance for users across multiple industries, such as finance, ecommerce, and development. The backup tool acts as the single source of truth, within which a centralized, current backup is preserved at all times. If calamity strikes, you won’t have to go hunting for copies of files, attachments, and codes. These live in a remotely accessible cloud location. Authorized employees can retrieve data as needed, and DevOps teams can perform restoration work from anywhere.
Note that costs may be expensive with these solutions. That may be a con as well, yet the pricing structures offered by many backup companies are predictable and consistent. Many offer scaling pricing solutions that support rapid growth. You’ll know what you’re getting, what it’ll cost, and how to budget accordingly.
Cons of Purchasing a Backup Solution
A clear disadvantage of going to a third-party is data storage. Backup platforms include support for data storage solutions that its developers choose to support—instead of letting you choose. This requires vetting before buying. It may also introduce storage fragmentation within your organization, should you be married to one specific tool. That applies to both geographical data locations (North America vs Europe vs APAC, for example) and storage vendors (S3, Google Drive, and others). You may need to invest in a backup solution that offers users more choice for their data storage locations.
Finally, you have less control over backup frequencies. Some tools can only back up at longer intervals. However, frequent changes to your projects in the wake of agile development may require more frequent backups. Daily backups might be required to ensure your team’s work is protected.
To Build or to Buy?
The choice to build vs. buy may not seem easy. However, carefully considering your priorities and needs will help steer your decision. Backing up GitHub remains essential in this day and age. Leading solutions, like Rewind, are there for those seeking a powerful third-party solution. If buying is your priority, we invite you to give us a try with a free trial.
 Tyler Charboneau">
Tyler Charboneau">